Hadoop目标可以概括为:
- 可扩展性:Petabytes (1015 Bytes)级别的数据量,数千个节点
- 经济性:利用商品级(commodity)硬件完成海量数据存储和计算
- 可靠性:在大规模集群上提供应用级别的可靠性。
Hadoop包含两个部分:
- HDFS:Hadoop Distributed File System(Hadoop分布式文件系统),HDFS具有高容错性,并且可以被部署在低价的硬件设备之上。HDFS很适合那些有大数据集的应用,并且提供了对数据读写的高吞吐率。
- MapReduce:Map/Reduce模型中Map之间是相互独立的,因为相互独立,使得系统的可靠性大大提高了。它是用调度计算代替调度数据。
常用的统计模型:
机器学习的算法有很多分类,统计机器学习在Hadoop上仅仅实现其逻辑是比较简单的。常用的统计模型可以大致归为下面两个类别:
- 指数族分布
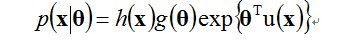
指数族分布是由最大熵的原则推导出来的,即在最大熵的假设下,满足一定条件的分布可以证明出是指数族的分布。指数族分布函数包括:Gaussian multinomial, maximum entroy。
指数族分布在工程中大量使用是因为它有一个比较好的性质——最大似然(Maximum likelihook, ML)估计可以通过充分统计量(sufficient statistics)链接到数据,要解模型的参数,即对做最大似然估计,实际上可以用充分统计量来解最大似然估计:
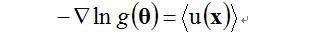
充分估计量大小是与模型的参数的空间复杂度成正比,和数据没有关系。换言之,在你的数据上计算出充分统计量后,最就可以将数据丢弃了,只用充分统计量。
Map Reduce统计学习模型
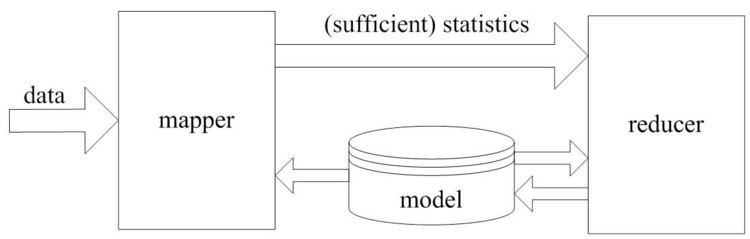
Map的过程是收集充分统计量,充分统计量的形式是u(x),它是指数族函数变换函数的均值。所以我们只需要得到
u(x)的累加值,对高斯分布来讲,即得到样本之和,和样本平方和。
Reduce即根据最大似然公式解出theta。即在mapper中仅仅生成比较紧凑的统计量,其大小正比于模型参数量,与数据量无关。在图中还有一个反馈的过程,是因为是EM算法,EM是模拟指数族分布解的过程,它本质上还是用u(x)解模型中的参数,但它不是充分统计量所以它解完之后还要把参数再带回去,进行迭代。